Scrapebox is a small tool also known as “The Swiss Army Knife of SEO” among those who are familiar with this tool. It is well known in the SEO community for its different capabilities, based on which it has established itself as the swiss army knife.
One of the must have tool in your arsenal which saves a lot of your precious time and makes your daily SEO task easier.
The cost of Scrapebox for $97 but you can download scrapebox for just $67 from BHW.
Quick History
This tool has been tested to its limit for automated link building which then ended with shit loads of spamming the internet. One of the rich feature of this tool is automatic blog commenters, which has the potential to blast thousands of blog comments to different websites that supports blog commenting. One reason how this software earned bad reputation in the world of SEO.
Fear not the weapon but the the paw that wields it
Scrapebox is a very powerful tool that cannot be underestimated. Besides blog comments spam, there are many different features in this tool that can be used to leverage your SEO strategy.
So do we need a VPS and Proxies to get started?
If you are a heavy user of Scrapebox then you should get a VPS. If you do not have a powerful machine, Scrapebox can slow down your computer so it’s wise to let this run on your VPS for days meanwhile you can perform your regular task on your local machine. Also, in case you have a slow internet connection or limited monthly quota for your internet you would like let your Scrapebox on your VPS.
Proxies? Yes, you need a lot of them!
Always use good proxies with Scrapebox. A proxy acts as a middle man for Scrapebox while grabbing data from search engines. Google won’t tolerate the same IP making multiple request to their engine, over a short time frame. That’s one reason we need proxies to save our IP from being banned.
There ain’t any fixed number of proxies that have to be used while using Scrapebox. This requirement depends on how hard you are going to hit Google, but 15-20 private proxies to kick start is OK. However, you can even use public proxies but they get banned very easily.
In this tutorial, you will learn how you can make the best use of this tool. Tools like these when used in the right way, help us dig out larger possibilities that can be used for our day-to-day SEO practice. Why not try that out, right?
Few warm up terms, before we kick start
Footprints: Imprints, such as strings of text etc ., from a web page which can be used to find similar web pages. For e.g “.gov” for government sites, “.edu” for education sites, “powered by wordpress” for sites using wordpress.
Seed list: A list of keywords or urls that you use initially. For e.g the list of keywords that you input into keyword tool to find more of them.
Link Extractor: Link Extractor add on helps you scrape the inner links and the external links of any urls. Not only that, it also has auto save feature, which saves the links extracted in a txt file.
Remove/Filter: This feature works straight forward. Filter out the things that you don’t need.
Vanity Name Checker: Web 2.0 platforms allow you to create a subdomain, which is also the url to your site hosted on those platforms. In most cases, the subdomain or the vanity name has rich keywords in it. Vanity Name Checker checks your keywords to see if accounts by these names are available for registration on popular Web 2.0 and Blogging sites.
How to use Scrapebox in 2020?
In this tutorial, I will list only those things that I mostly do with Scrapebox. There are various other features that you can explore and level up your game with this tool. Below are the things that I do mostly:
Generate keyword ideas
Find expired domains
Find expired web 2.0 accounts
1. Generate Keyword Ideas
Keywords research is one of the important steps that should be considered in the initial stage of your SEO strategy. When you miss out the proper keyword research, it is obvious that no matter how hard you try, your website is not going to make you money. Simply because, you are not targeting the important keywords that actually converts and you will be missing out your actual market.
So how to use Scrapebox for keyword research?
Using Scrapebox you can discover scrape and create a list of keywords which can be helpful to find some great long tail keywords and LSI keywords.
All right, let’s do this!
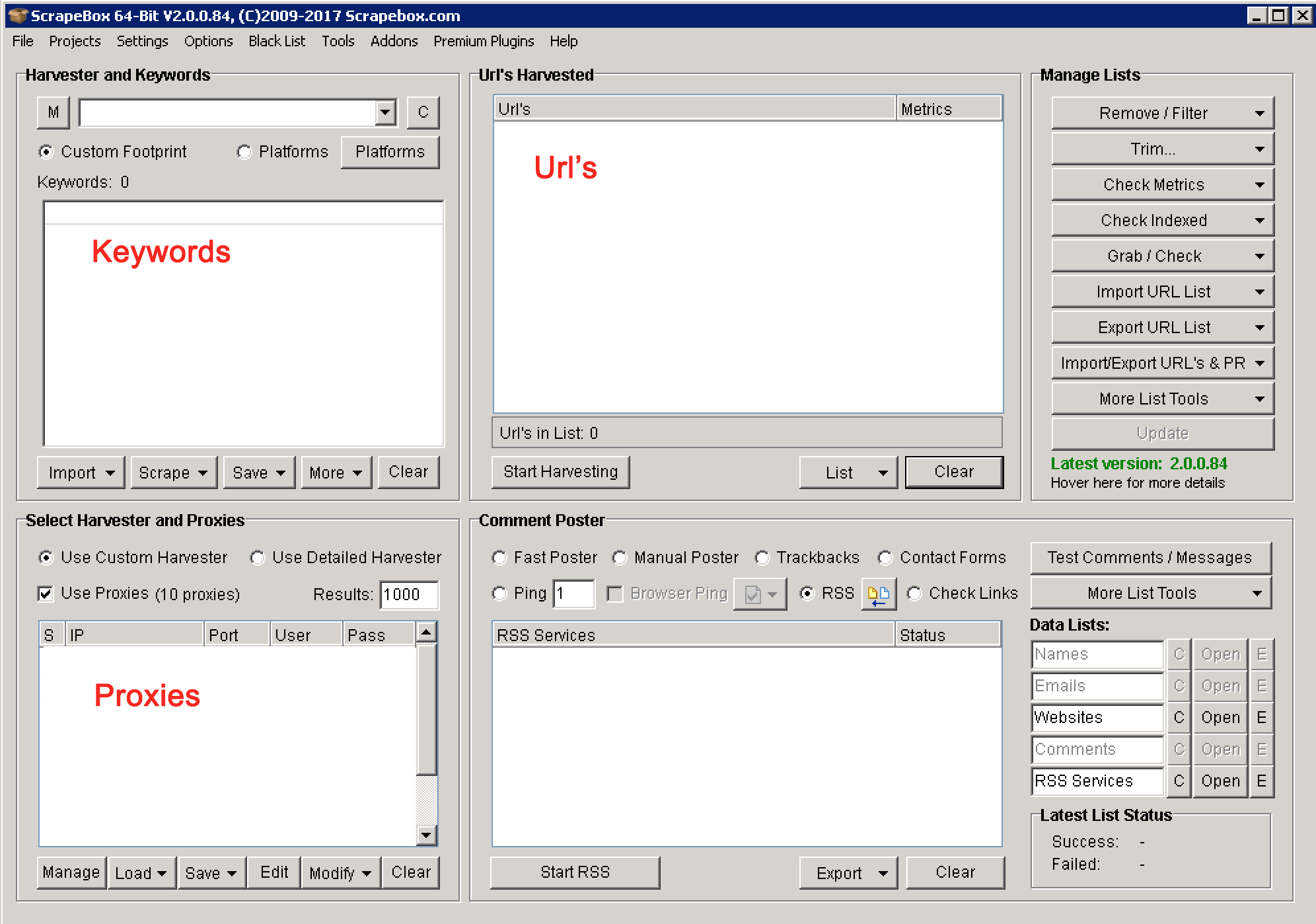
Scrapebox has an inbuilt Keyword Scrapper that scrapes keywords from different engines depending on your seed list of keywords. Click the keyword Scrapper to get started.
Now the keyword scrapper interface pops up. It’s extremely easy to understand the interface.
Add your seed keywords. Select the sources so that Scrapebox can scrape from those sources. There are additional options such as keyword prefix/suffix next to the “Click to Select Sources”.
Hit the “Start” button.
Within the seconds the keyword scraper will scrape a list of related keywords for you. Use these results as your new seed keywords by using the “Transfer Results to Left Side” option and scrape again. Boom! More keywords. Not to mention, you can repeat this process until you have a big keyword list.
What to do with the keywords?
Here are few things that you can use the keywords for:
Add them to the google keyword planner and check. This is where you can discover some hidden long tail keywords. You can then use the final keyword list to other keyword tools like Semrush, Longtailpro, Kwfinder etc.
Use the list to harvest urls for backlink opportunities or to find expired domains.
Tip: Make use of keyword tool like keyword.io to generate a list of your seed keywords. And then feed your Scrapebox to generate another huge list. More keywords, means opportunities for finding gems.
Add your keyword. Select google as the engine and select the country. Hit Search.
Within seconds you will have a list of keywords ideas suggested by this tool. Select those keywords that makes sense to you.
With an account, you will have the features to download and copy your list. But, I will just copy the result to clipboard for now.
Open up your Scrapebox keyword scraper and load it with this new list of keywords. And scrape again.
2. How to find expired domains with Scrapebox?
Expired domains can be very useful. It’s not just about expired domains, it is more about good expired domains with good SEO metrics that includes DA/PA (Domain Authority/Page Authority), TF/CF ( Trust Flow/Citation Flow) and a clean link profile.
Basically, expired domains already have some powerful backlinks pointing to them, with the help of which, you can rank your site easily. Expired domains are mostly used to build up a PBN ( Private Blog Network).
I am going to show you 4 different methods to find expired domains using Scrapebox:
(i) Expired Domain Finder (Premium plugin) (ii) Scrapping urls (iii) Ahrefs/Majestic (iv) Google Search custom date range
There are many other tools out there, which cost high monthly prices. I tried few tools that even promises spam checking the list of the expired domains. But in the end, I had to re-do this part manually since some of the domains were heavily spammed in the past and those tools actually gave green signal to those domains. One reason why you must not depend on tools solely.
Finding expired domains like a BOSS!
How to use?
I am covering only the basic on how to use this plugin here. There are various options available to play with. Checking Majestic and MOZ metrics, social shares and even DMOZ entry is possible with this handy plugin. (update:DMOZ listing is offline from March 14, 2017)
We will feed a list of urls to this plugin and the plugin will find out any expired domain linked to those urls. Be careful with the scrape level option. If you go beyond level 2, chances are high that you end up with irrelevant expired domains.
But if you don’t really care about the relevancy and just want to find as much domains as you can, then you know this plugin got your back!
Let’s grab some seed urls to start with.
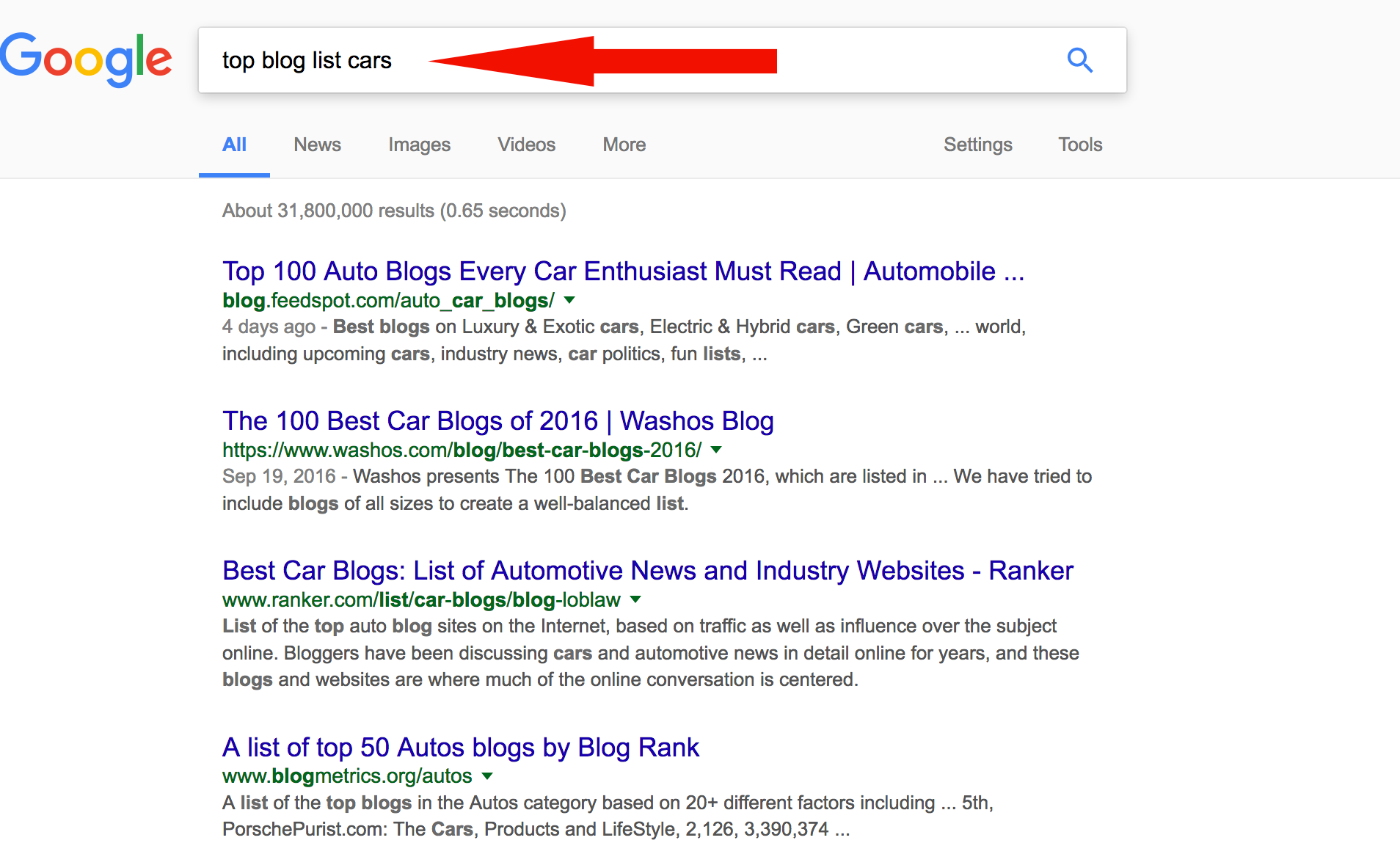
Google for “top blog list your keyword”. Lets say my keyword is “cars” here.
e.g : top blog list cars
Check with the top 10 results or you can go down to a page deeper and list up the urls that you think works for you. Create a list of those urls and save them in a txt file.
You can either import the file or copy from the clipboard. We are going to deep crawl these urls.
As seen in the image above, you can load the urls in different way. Select what is easy for you.
Setting up the plugin
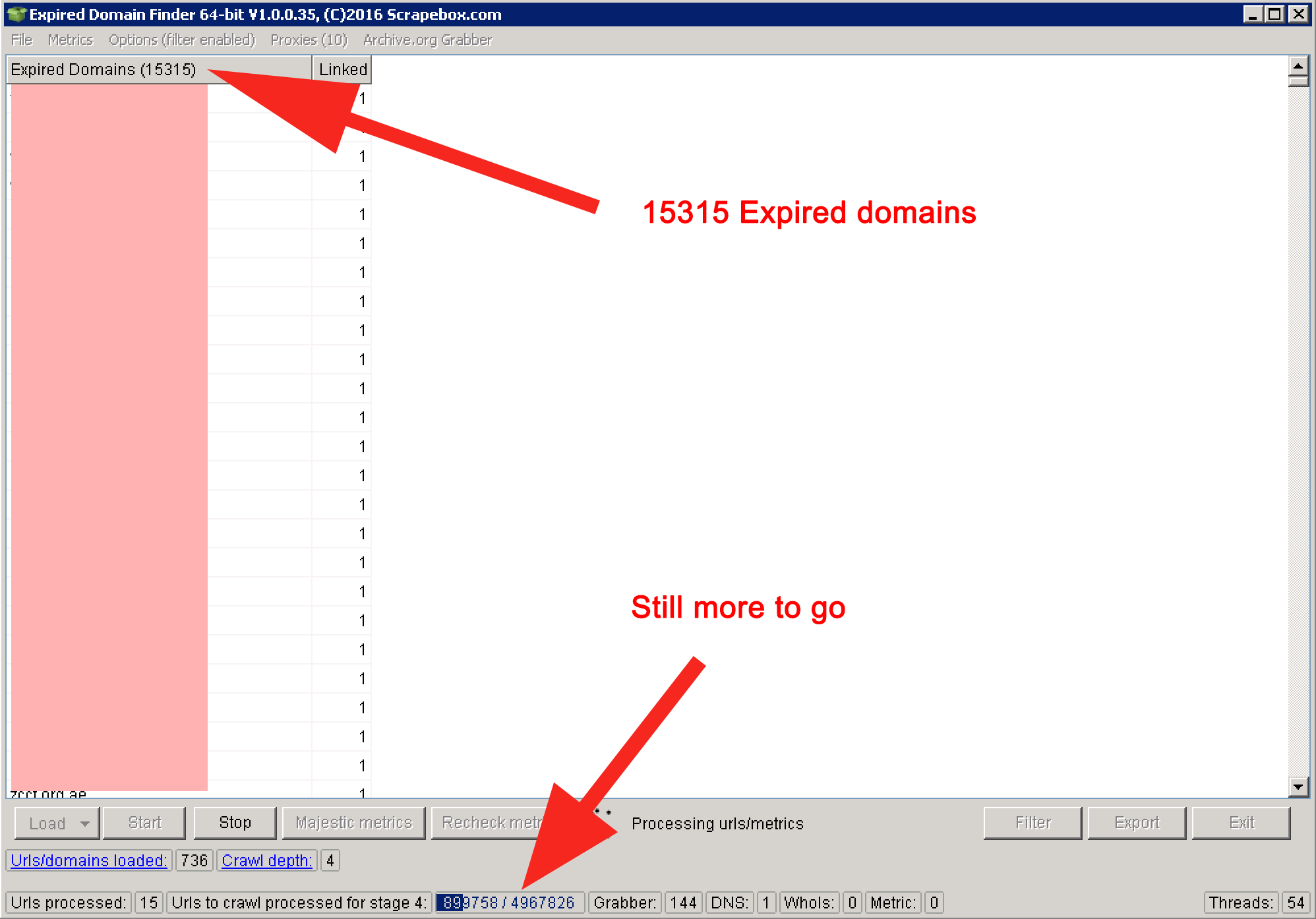
Set up real time filters. For e.g. If you are only looking for specific domain extension then you can set your own filters. Adjust the crawl depth. I have set that to level 5 for now so that we can get maximum number of expired domains. The maximum level is 20. Don’t set the crawl depth to the max if you don’t know how it works or else your VPS will run out of memory and your plugin may crash in the middle.
One great feature this plugin has is, it auto saves your progress. So you can still retrieve the earlier results if in case the plugin gets crashed.
Click start. Each expired domain discovered during the crawl will be listed up in the result box until the job is done. You can export the final list to your folder. The list can be imported back to the plugin for metrics check too if you do not want to check it during the crawling process. Either way, it works great!
Now you have a final list of expired domains.
Tip: You can even try out with a Wikipedia page or pages from sites like CNN, BBC, DMOZ etc. This way you may end up with expired domains linked from those big websites. Your results depend mostly on the urls that you feed your SB and there is not any secret sauce except experiments. Yeah! Lots of them.
(ii) Scrapping urls:
Using Scrapebox we can scrape hundreds of urls within minutes. Always make sure you have proxies enabled.
How to harvest urls?
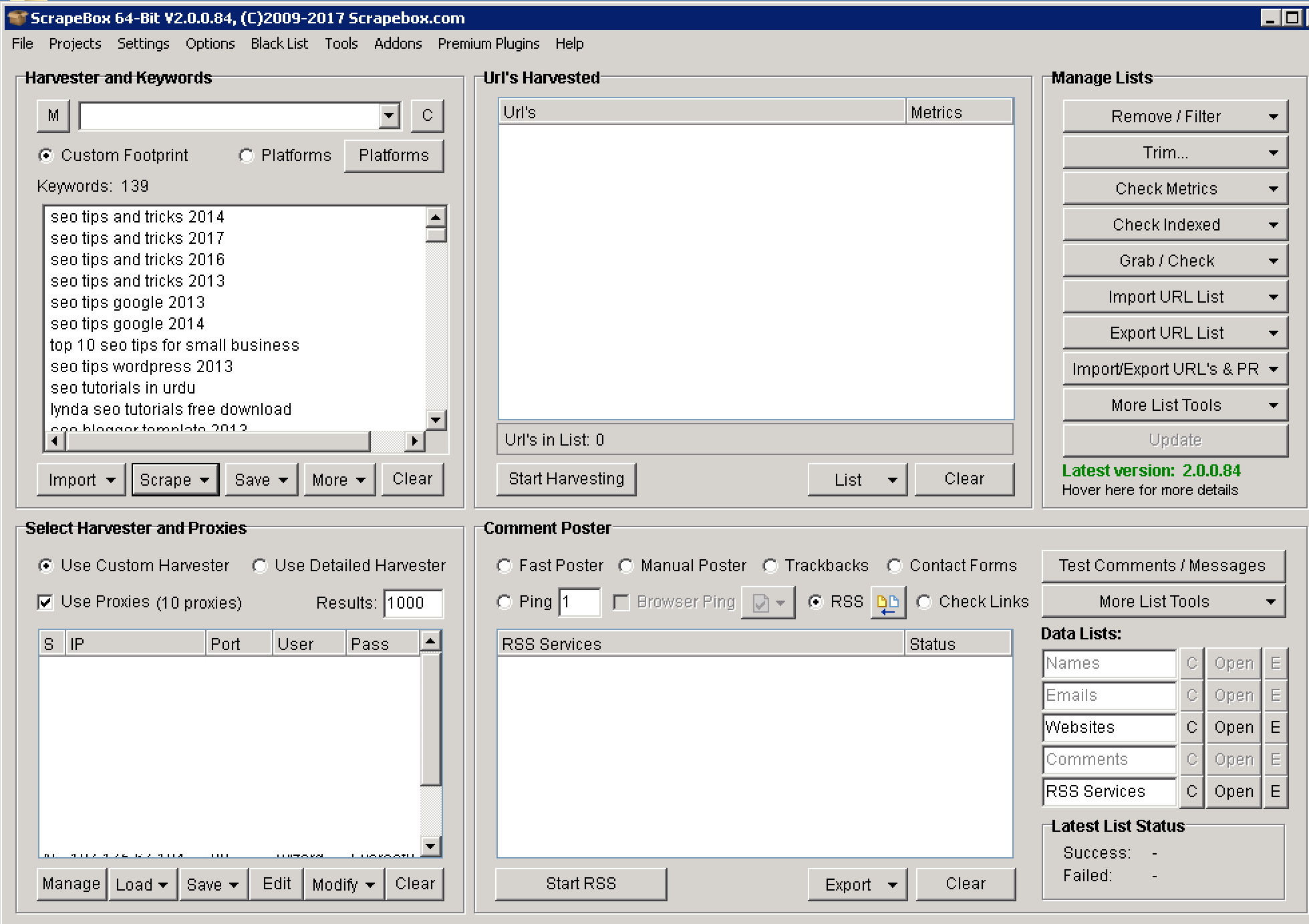
Import or copy paste your keywords. Scrapping keywords and generating a master list has already been covered above. You can select any specific platform listed in Scrapebox by selecting the “Platforms” option. For this tutorial we will just go with the custom footprint.
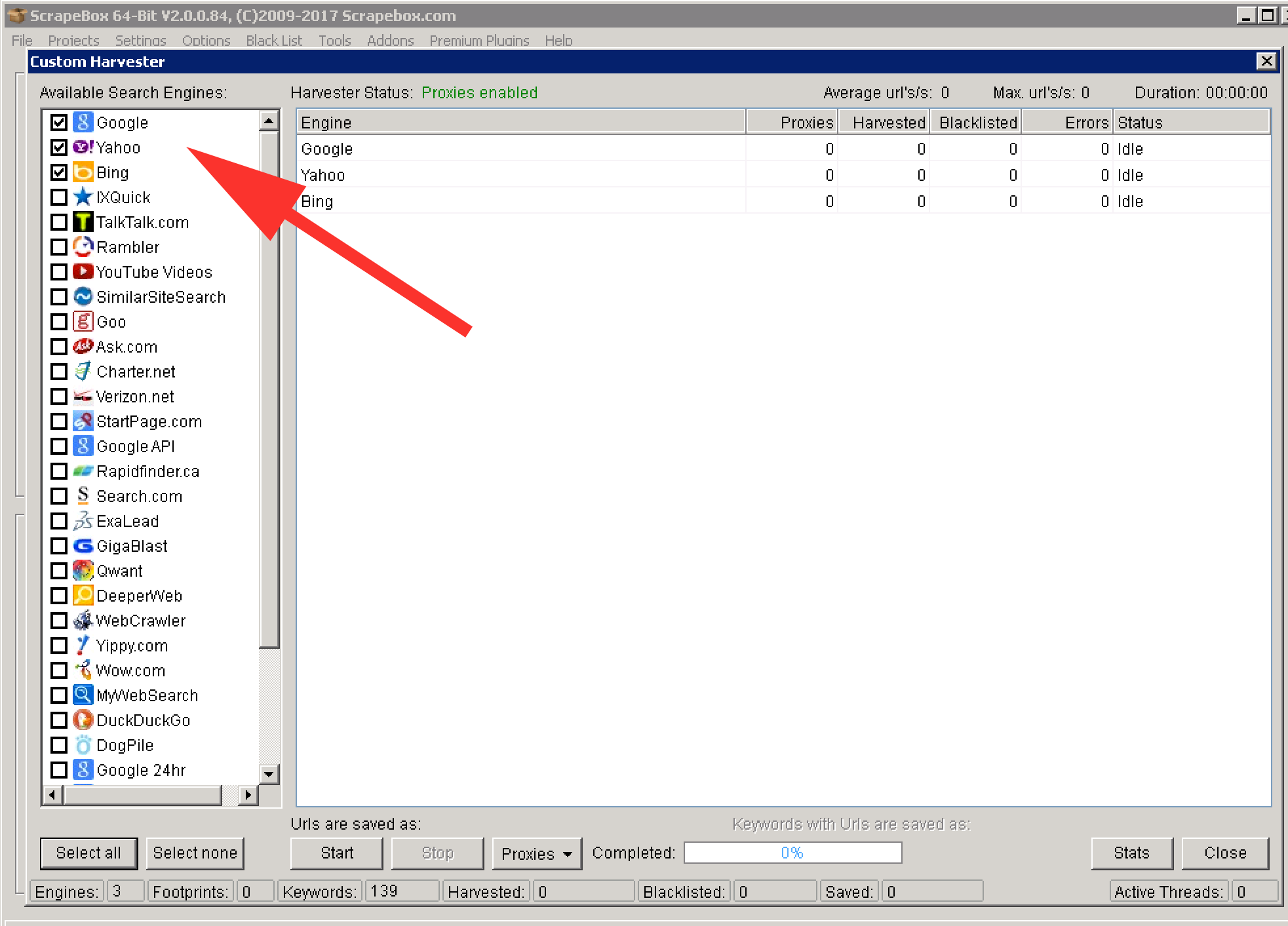
Click “Start Harvesting”. Select the search engines and again, make sure you have proxies enabled. Press “Start”.
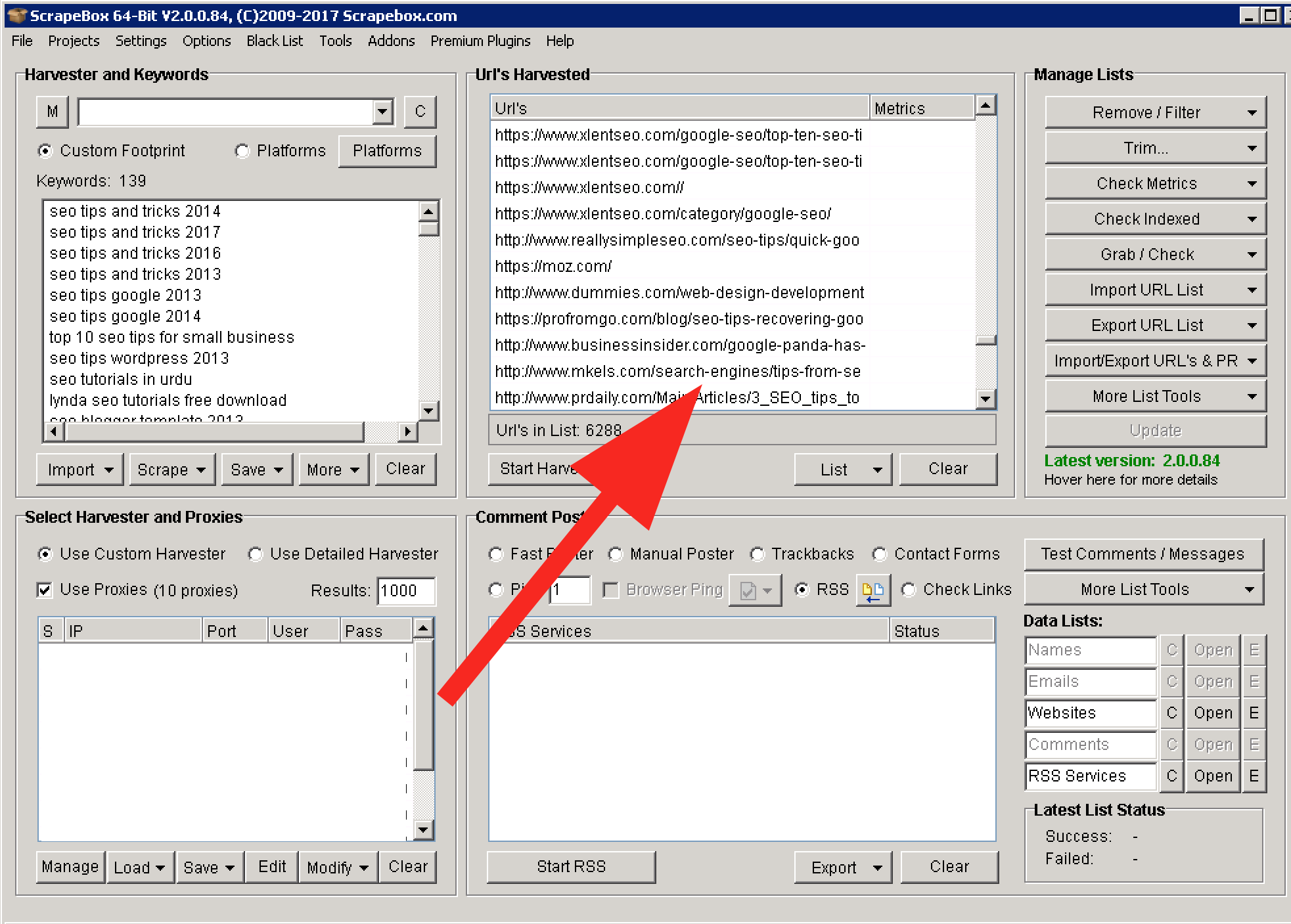
Wait for the harvest to complete. The results will appear under “Url’s Harvested”.
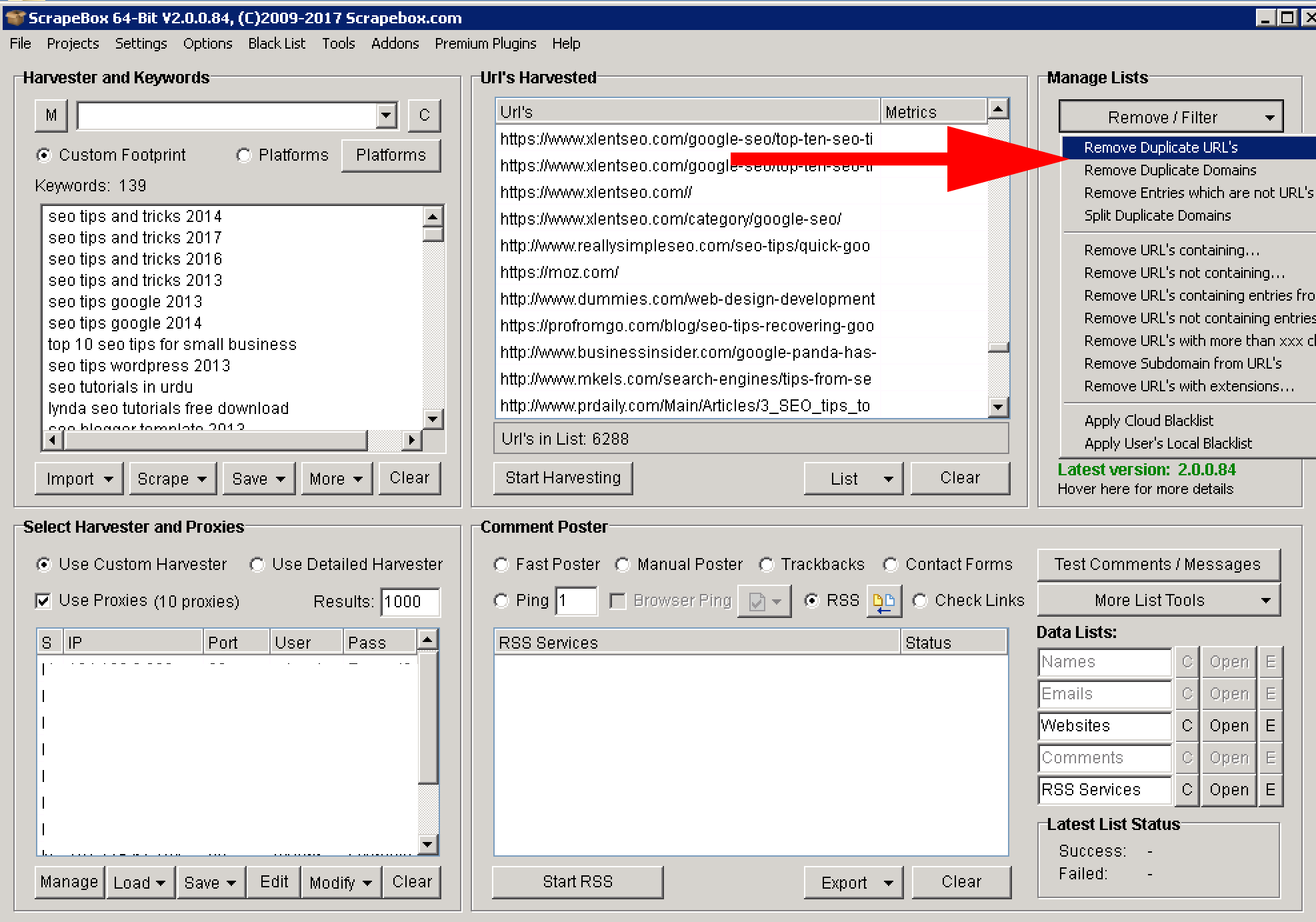
Remove duplicate URL’s using the filter. This filter has many other options too. Use them to clean your list.
Export your list to your target folder
These are the basic. You can go to next level by using different combination of your custom footprints and keywords.
I will show you an example.
Insert your footprint in the footprint field. It is located inside the red border in the image below.
In the example below, we are trying to find .edu websites that have pages about the keywords you inserted in the keyword fields. The keywords will get combined with the footprint and Scrapebox will search for the following in the search engines:
site:.edu seo site:.edu training site:.edu seo tutorial site:.edu seo tips site:.edu search engine optimization
Isn’t it cool?
Now, with your seed list of urls ready, let’s go and find some expired domains.
We are going to use the link extractor plugin to find more links which means more domains to check with.
Follow the steps below:
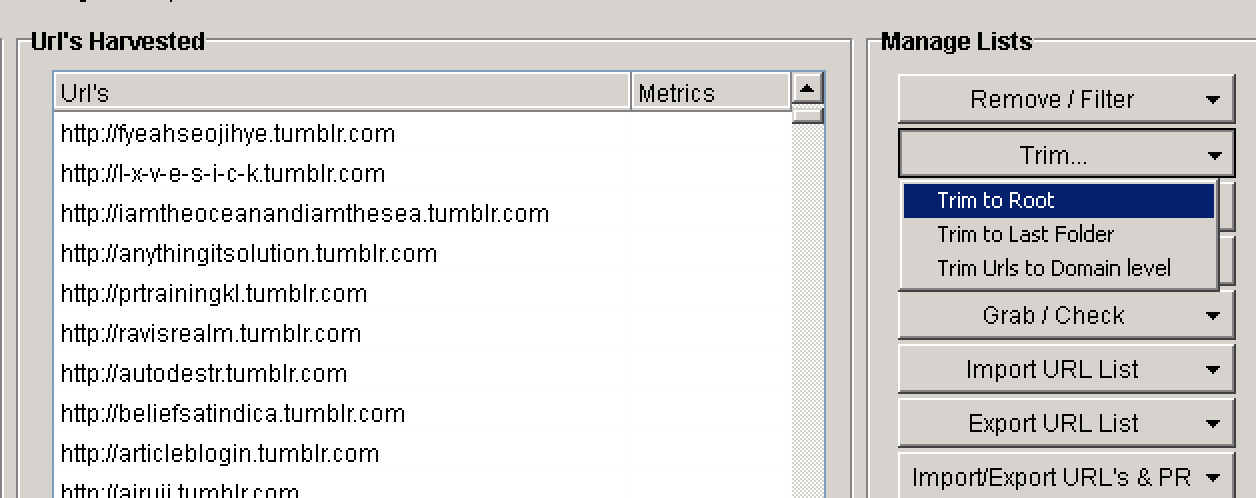
1. Load the urls in the link extractor 2. Extract the internal links 3. Remove any duplicate entries 4. Load them to the link extractor and Extract the external links 5. Import the urls 6. Trim to root 7. Check the domain availability 8. Save the list of available domains
(iii) Ahrefs/Majestic:
1. Find big authority sites 2. Export the back links using tools like Ahrefs and Majestic 3. Save the list of backlinks 4. Load them into Link extractor and check for the inner urls 5. Save the list and do a external link check using link extractor 6. Use the filter to clean your list 7. Trim to root 8. Check the domain availability 9. Create your final list
(iv) Google Search custom date range :
Google Search custom date range filters can be used to find older contents within specified date ranges. Content published years ago should have older domains linked to it. Using this custom date range filter, we will create a list of urls indexed years ago.
In this example, we will find “seo tutorial” articles published between 2004-2005.
Head over to google.com and search for your keywords. Click the “Tools” menu and select “Custom Range”
Add 1/1/2004 in the ‘From’ field and 1/1/2006 in the ‘To’ field. Hit “Go”.
Google will now show the related entries within the starting of 2004 and the first day of 2006.
Grab all of the urls in the SERP.
Save your time by setting the result per page setting to display 50 urls per page.
Open google.com. Find out the “Settings” in the footer. Settings > Search settings > Results per page > 50 > Save
Use browser extension like Link Klipper to extract all the urls in a .csv file.
What to do next?
Head over to method (i) and (ii) and find out more link building opportunity.
Tip: You can also use your final list in the expired domain finder plugin. Break down your large list into smaller chunks before you add them to the plugin. This way you don’t run out of memory on your VPS.
3. Finding expired Web 2.0 accounts
Web 2.0 sites are free to use. Few examples of web 2.0 sites are WordPress, Tumblr, Weebly, Blogspot, etc. You can create your own website or a blog on these platforms and add a link back to your website that you want to rank.
Why use web 2.0?
Web 2.0 domains have huge domain authority. Creating a page under those domains will easily gain page authority over a short time with less effort. We will then use these metrics to rank our main websites by placing a link from our web 2.0 pages to our main websites.
Why not just find some expired web 2.0 accounts and start right away? Find accounts with good metrics and register them for our own good.
Preparation
E-mail accounts: To register the expired accounts. Scrapebox: We will use Vanity Name Checker, free Scrapebox add-on Proxies: At least 20 private proxies Keywords: Get a big list of keywords.
Tumblr is one of the popular platform and I will show you how to find expired Tumblr accounts using Scrapebox. The method is similar for other web 2.0 sites as well.
Steps:
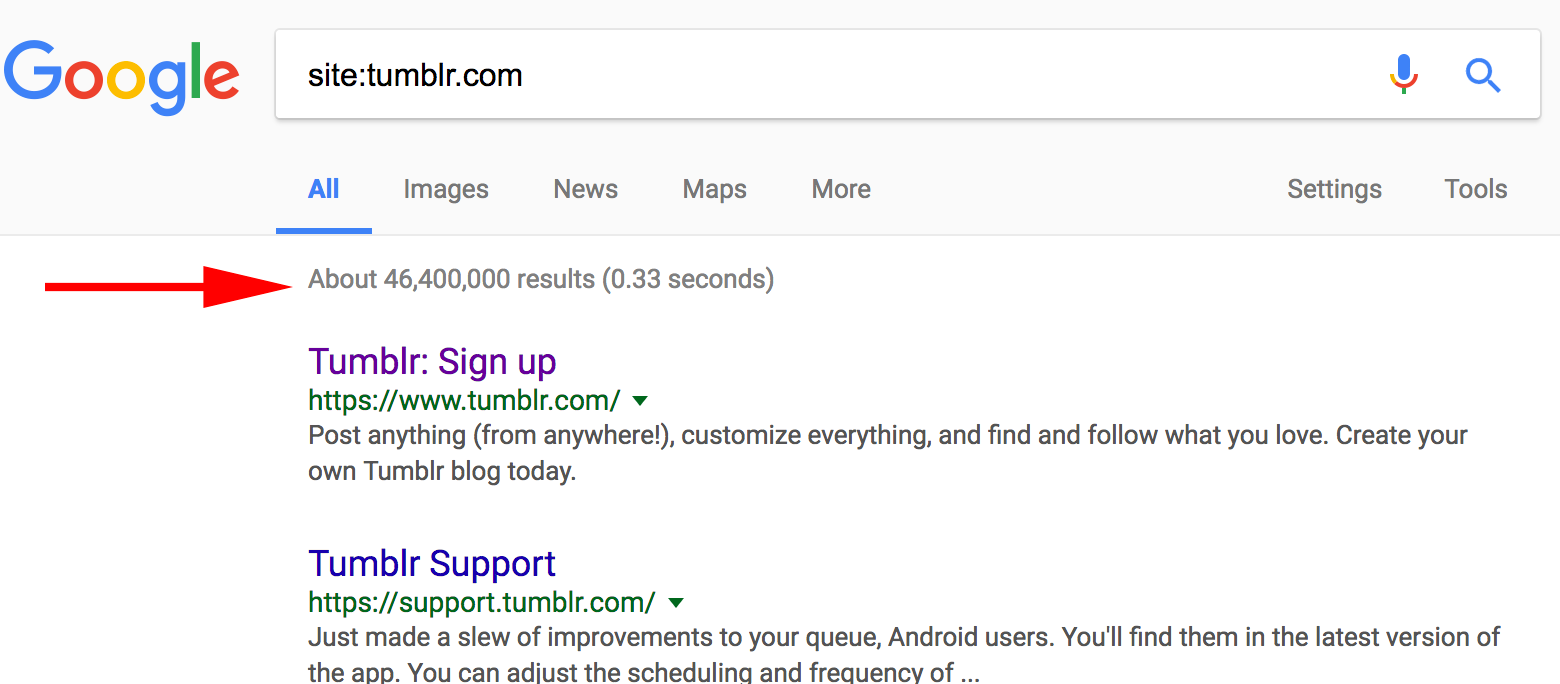
Start with adding “site:tumblr.com” to the custom footprint bar. We are going to scrape tumblr.com. Make sure you check the custom footprints.
“site:” It’s a google search operator which returns an estimated count of the number of pages indexed for that domain. See the screenshot to see the command in action.
Load your keywords.
Click “Start Harvesting” button to start.
Let it run, meanwhile you can grab some beers or watch some movies or carry on with your regular works.
Harvest complete! What next?
Cleaning the List:
Trim to Root.
Now we are left with unique urls. This step is optional but you can go another step ahead and remove any urls that you think do not fit there. This can be done with the “Remove/Filter”.
Checking for available accounts:
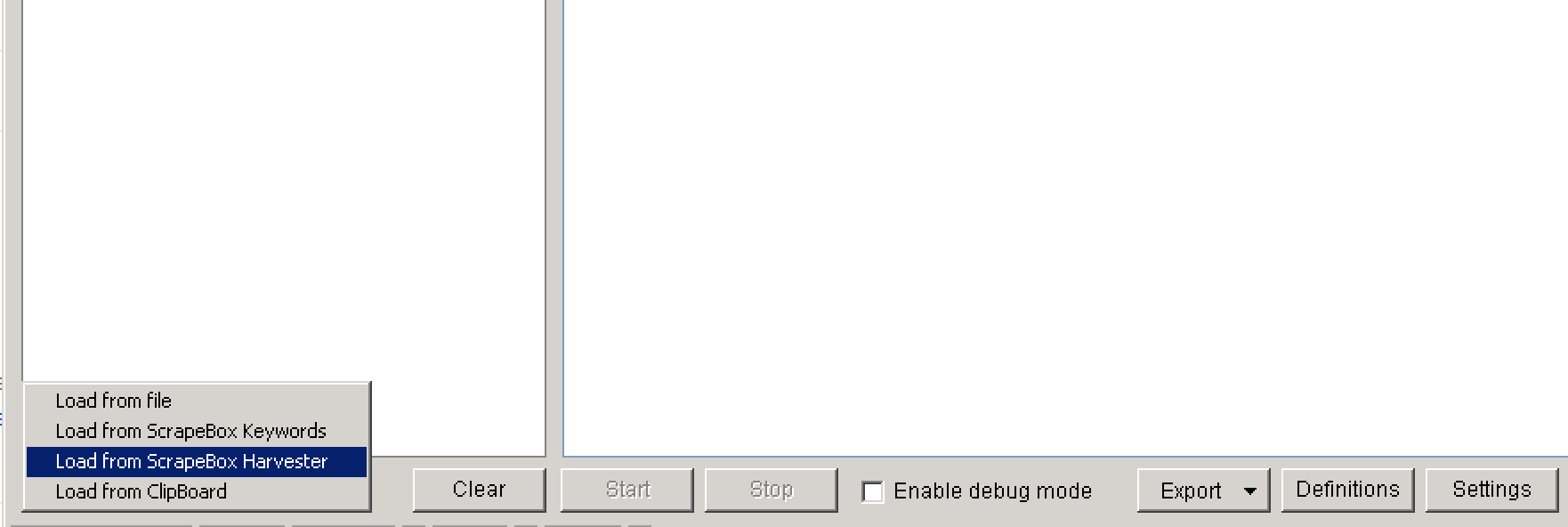
1.Open Scrapebox Vanity Name Checker under the Addon menu.
2. Load your list using “Load from ScrapeBox Harvester” option.
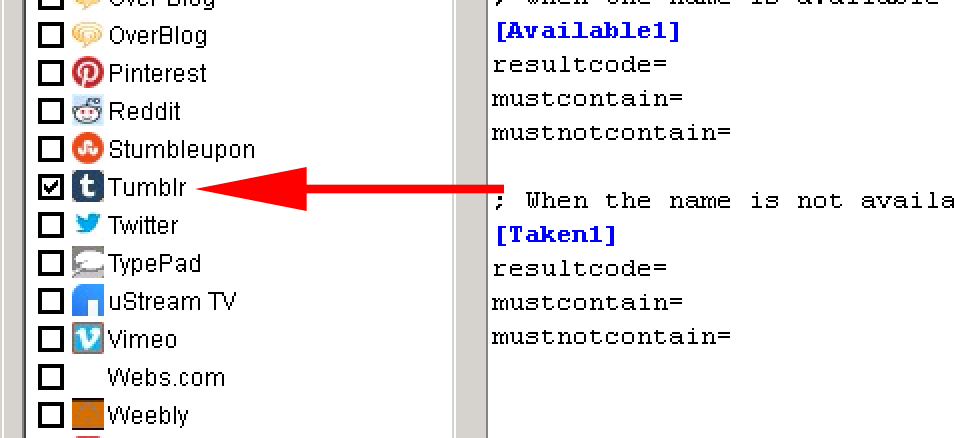
3. Click on “Settings” and uncheck all of the Web 2.0 sites except for Tumblr.
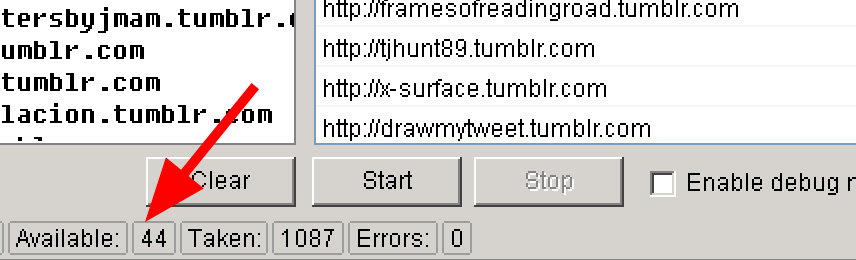
4. Let it run until the process is complete. You will be able to see how many accounts are available to register.
5. Select “Export all available urls” from the Export menu and save it to your folder.
6. And you are done!
Pat yourself on your shoulder!
Picking up the best ones
Filter and register only those accounts having better metrics.
MOZ PA: Head over to “Authority Checker” under the Addon menu. You will need some Moz accounts for this. Add your api details from the accounts menu. Import your urls and let it run.
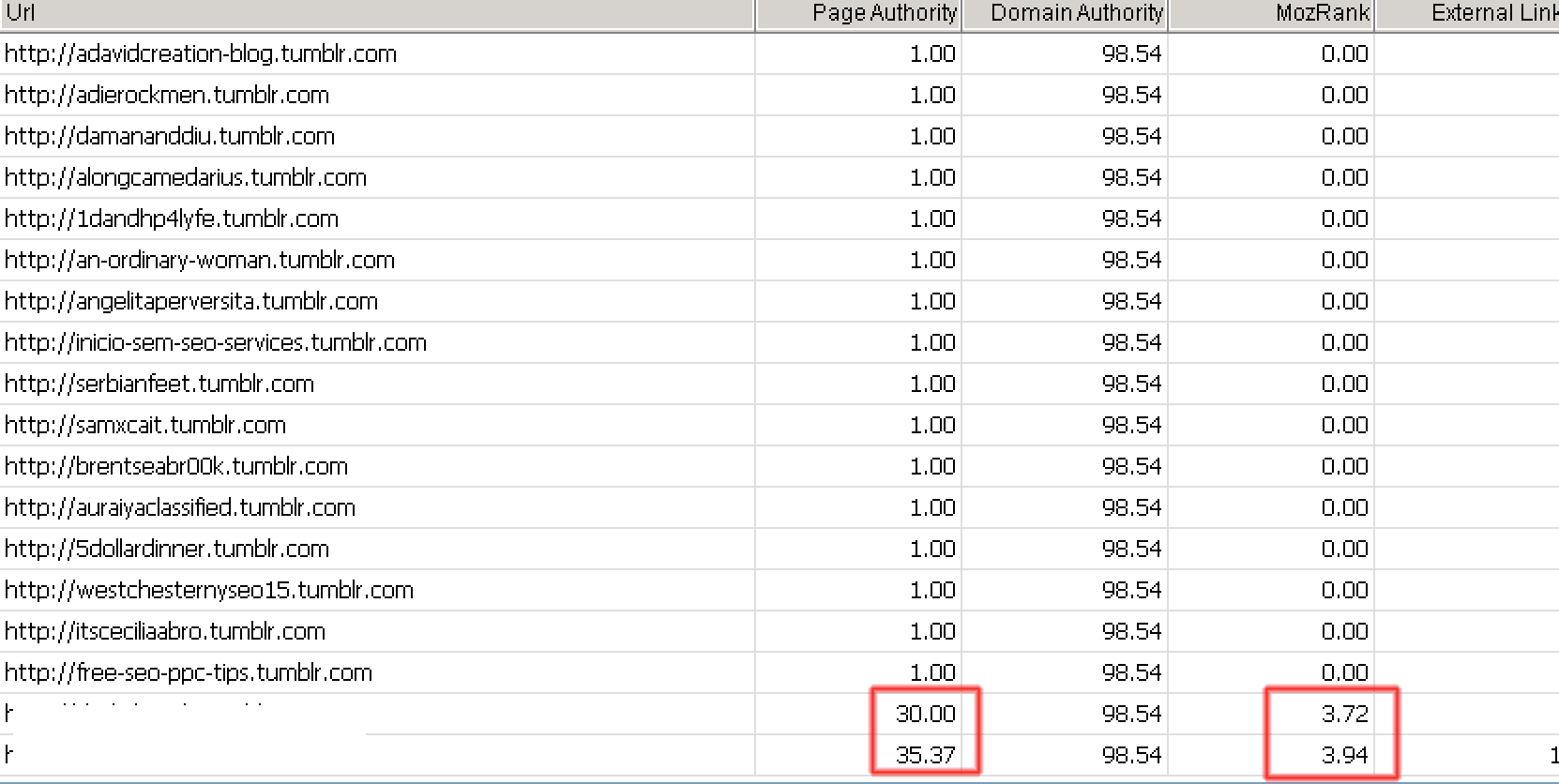
We are dealing with tumblr subdomains here. So the DA( domain authority) should be same for all of the urls. What we are checking here is, page authority! Page Authority above 30 is good to go.
You can use free tools to bulk check the PA of your urls. You can check the list below:
Majestic TF/CT: Majestic TF/CF are another metrics that I would like to check. Not only that, these tools also provide better information on links compared to MOZ. TF/CF above 10 is a good signal. When it comes to external links, the more, the better.
Register the available accounts:
subdomainname.tumblr.com where the “subdomainname” is the username.
E.g: thiscoolblog.tumblr.com
You need to try to register with “thiscoolblog” as your username.
Don’t register too many accounts using the same IP. You may end up losing all the accounts. Use private proxies or VPN to register accounts. 3 -5 accounts per IP should be all right.
HELL YEAH! That’s how we nail it down!
Note: Sometimes, some accounts that seems to be available from the Vanity Name Checker may not be available when you try to register the username. Don’t cry over it. Move on and harvest with another huge list of keywords. That’s how this game goes on!
What can you do with expired domains, anyway?
Depending upon the quality of the domains there are many things you can do with expired domains.
Here are few good examples on what you can do with the expired domains:
Build PBN – You can create your own private blog network with few domains and add more domains over time.
Main Money site – A new site takes time to rank. If your expired domain qualifies for a good domain name with good metrics you can use it as your money site. With the established external links pointing to it, you won’t need much time to rank and bank.
Cash it – You can make some cash out of it. Internet Marketers who build their own PBNs are always looking for good expired domains. The price depends on the quality of the domains. You can even use the godaddy auction to sell your domain.
Final Thoughts:
Scrapebox is a very powerful tool. It’s not just about blog commenting and scraping search engines. With all the free features that come with it, you can easily work on it to perform tasks that can take a lot of time if done manually.
Remember this is a learning curve!
Everything covered here is what I mix up and do. These are the proven techniques that work for me. And it isn’t necessary that it will work 100% for you. But this guide will help you generate ideas that you can utilize on your learning process.
Try using different google search operators in your footprints.
Mix things up! Footprints, Keywords, Seeds, Everything!
Hey just wanted to give you a brief heads up and let you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same outcome. Been trying to figure out whats in the images that didn’t load properly.
Aw, this was a really good post. I procrastinate a whole lot and never seem to get anything done. I have this habit of giving up on tools. Are you a heavy user of Scrapebox? I had few lucks with spammmmmmming in the past when the churn and burn sites used to rank in no time
|A link builder who engages in link building services always looks for relevant sites which are similar to the theme of the client’s site. SB makes it very easy when it comes to link building. Thanks for the wonderful post.
Link buiding is the most important part of any seo campaign.. The more link building coming to your site the better it ranks in the search engines and the higher your site will climb up the search results. You could have the best looking site anyone has ever seen and without a great link building campaign no one would ever know your site existed.
Scrapebox used to work for all kind of dirty works in the past but now this tool is not as useful as it used to be before.
Very nice post. I just stumbled upon your weblog and wished to say that you have a very informative post on Scrapebox. I have been using this tool for few months and i came to know about the premium plugin as well.
Excellent post Pravash! This is an awesome piece of SEO tools ever create so far. People just take it for spamming the web but if you look at the brighter side no one fucking beats this!
Great post for beginner’s to understand the power of Scrapebox. Just to add something about removing the duplicate URLs/domains from the harvester lists. You now have the option to auto-remove the duplicates after every harvesting done on Scrapebox. Just check under “Options” you will see the auto-remove function. So manually clicking on remove duplicates is not necessary anymore. I’m using 2.0.0.9.4 version of Scrapebox by the way.

















Hey just wanted to give you a brief heads up and let you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different browsers and both show the same outcome. Been trying to figure out whats in the images that didn’t load properly.
Is the scrapebox plugin worth the money?
It is! I bet 😉
Aw, this was a really good post. I procrastinate a whole lot and never seem to get anything done. I have this habit of giving up on tools. Are you a heavy user of Scrapebox? I had few lucks with spammmmmmming in the past when the churn and burn sites used to rank in no time
SB is one of the important tool in my Arsenal. It save a lot of my time. Very very powerful tool. So you can say that I am a heavy user of Scrapebox
You expressed it perfectly!|
Thank you 🙂
|A link builder who engages in link building services always looks for relevant sites which are similar to the theme of the client’s site. SB makes it very easy when it comes to link building. Thanks for the wonderful post.
🙂
Link buiding is the most important part of any seo campaign.. The more link building coming to your site the better it ranks in the search engines and the higher your site will climb up the search results. You could have the best looking site anyone has ever seen and without a great link building campaign no one would ever know your site existed.
Scrapebox used to work for all kind of dirty works in the past but now this tool is not as useful as it used to be before.
Very nice post. I just stumbled upon your weblog and wished to say that you have a very informative post on Scrapebox. I have been using this tool for few months and i came to know about the premium plugin as well.
Keep writing
Dein Beitrag gefällt mir sehr gut! Weiter so 🙂
Who dominates the truth, also dominates the internet market.
Looking forward to reading more. Great post.Really thank you! Great.
Excellent post Pravash! This is an awesome piece of SEO tools ever create so far. People just take it for spamming the web but if you look at the brighter side no one fucking beats this!
A MUST HAVE TOOL! I MUST SAY!
Can’t agree more 🙂
excellent job on this article! Your points are well formed. cool read. Thumbs up!
I really enjoyed reading the use of SB post. Be sure to keep it up. May god bless you !!!!
Welcome
Rly good 😀
Brilliant article 😀
Wondering if this Scrapebox works in 2017 or not.
Depends on how you use it. SB can save you lots of time on different purpose.
Nice post about Scrapebox…..Good amount of guidance here…
Hope you find it useful
Great post for beginner’s to understand the power of Scrapebox. Just to add something about removing the duplicate URLs/domains from the harvester lists. You now have the option to auto-remove the duplicates after every harvesting done on Scrapebox. Just check under “Options” you will see the auto-remove function. So manually clicking on remove duplicates is not necessary anymore. I’m using 2.0.0.9.4 version of Scrapebox by the way.
When I wrote this post, I think I was using the older version of SB. Thanks for spotting 🙂
Cheers